Overview¶
django_analyses provides a database-supported pipeline engine meant to facilitate research management.
A general schema for pipeline management is laid out as follows:
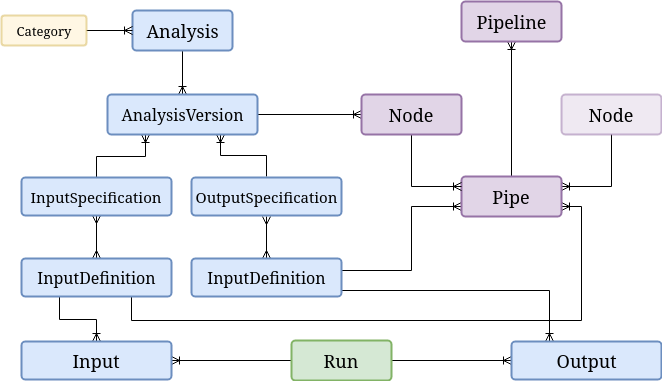
Analyses¶
Each Analysis may be associated with a number of
AnalysisVersion instances, and each of
those must be provided with an interface, i.e. a Python class exposing some run()
method and returning a dictionary of results.
For more information, see the Simplified Analysis Integration Example.
Input and Output Specifications¶
InputSpecification and
OutputSpecification
simply aggregate a number of
InputDefinition
and OutputDefinition
sub-classes (respectively) associated with some analysis.
Input and Output Definitions¶
Currently, there are seven different types of built-in input definitions:
and two different kinds of supported output definitions:
Each one of these InputDefinition
and OutputDefinition sub-classes
provides unique validation rules (default, minimal/maximal value or length, choices, etc.), and you
can easily create more definitions to suit your own needs.
Pipelines¶
Pipeline instances are used
to reference a particular collection of
Node and
Pipe instances.
- A
Nodeis defined by specifying a distinct combination of anAnalysisVersioninstance and a configuration for it.- A
Pipeconnects between a one node’s output definition and another’s input definition.
For more information, see Pipeline Generation.
Runs¶
Run instances are used to keep a record of every
time an analysis version is run with a distinct set of inputs, and associate that event
with the resulting outputs.
Whenever a node is executed, the value assigned to each of the
InputDefinition
model’s sub-classes detailed in that interface’s
InputSpecification is
committed to the database as the corresponding
Input model’s sub-class instance.
If we ever
execute a run with identical parameters, the
RunManager will simply return the
existing run.